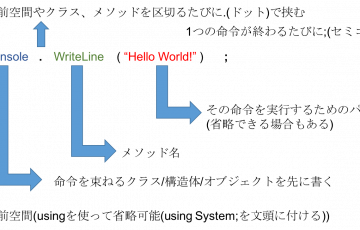
.NETには参照型と値型のオブジェクトがあります。メソッド等でデータのやり取りをする際に、refやout,inがなぜ必要になるケースがあるのか、しっかり理解しましょう。
[おさらい]メモリの構成
まずパソコンの中の処理を知る必要があります。

プログラムが読み込まれるときにまず行くところはメモリです。そして実行する部分を選別して取り出し、それをレジスタの中に移動させます。
なぜこのような工程が必要になるかといいますと、データの転送速度は記憶装置によって大きく変化し、処理の高速化の重要な役割をしているからです。
記憶装置別の転送速度は以下のようになっています。
| レジスタ | RAMメモリ | HDD | |
| 容量 | 128MB | 8GB | 1TB(1024MB) |
| 転送速度 | 数十GB/秒 | 4GB/秒 | 100MB/秒 |
| アクセス数 | 大量にある | 比較的多い | 少ない |
| データの記録 | 電源を切ると消えてしまう | 消えない | |
数値はあくまで例ですが、このような感じです。
レジスタはCPUから最も近い位置にあり、なおかつとても高速です。
ただしとても高価で大量に積むことはできません。
それを補助するためにあるのがRAMメモリ(主記憶装置)です。こちらも高価ですがレジスタほどではなく、容量も最近だと8GBや16GBが出ていますね。
しかし、レジスタとRAMメモリは電源を切ると中身のデータが消えてしまいます。(揮発性)
データが消えられると困るものは、HDDやSSDなどの補助記憶装置に記録されます。
仮想メモリのお話し
最近のパソコンではもう使われなくなってきている仮想メモリ、これは主記憶装置すらあふれ出るデータを補助記憶装置に保存してしまおうというものです。
ただし、補助記憶装置はRAMメモリからすると非常に低速で、使うべきものではありません。
RAMメモリから補助記憶装置にデータを移動させることをスワップといいます。
型によって決まっている
クラスと構造体ってありますよね。両方とも変数やメソッドをまとめたものみたいなものですが、ここに値型と参照型の違いがあります。
| 構造体(struct) | クラス(class) | |
| データの大きさ | 小さい(4KB以下) | 大から小までなんでも |
| 格納される場所 | 主記憶装置 | |
| 速度 | 速い | 遅い |
| 代表例 | int, float, booleanなど | クラスのインスタンス |
とこのようになっています。速度になぜ違いが出るかは後述しますが、気にする必要はさほどありません。
参照型とは
まず、レジスタは大量にデータを入れることができません。格納するデータは最小限に抑えるべきです。
なので、レジスタには以下の役割があります。
- 命令するメソッドのコード、パラメータのオブジェクトを置く
- 返ってきた戻り値を一時的に置く
- よく実行するコードをキャッシュしておく
というようになっています。
この1番が大事な部分で、メソッドを実行する際は必ず、それに関連するデータがレジスタに置かれます。
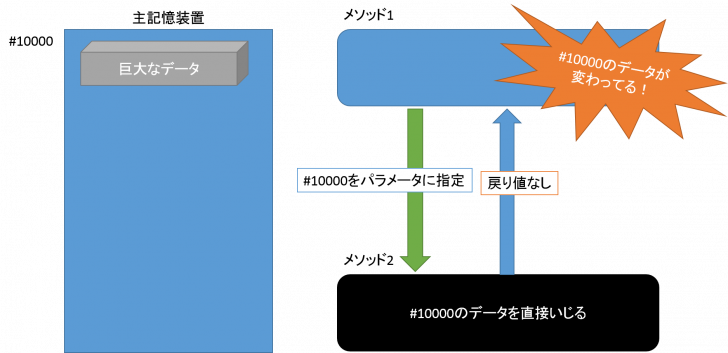
ですが、たまに巨大なデータがメモリに置かれることがありますよね。例えば数十MBの画像ファイルを編集するプログラムなんかは、数十MBのメモリを確保する必要があるわけです。
しかし、それをレジスタにすべて持っていくのは無理があります。ではどうするかといいますと、そのデータがあるメモリのアドレスをレジスタに記録するのです。

このように、画像データはメモリの中に、その代わりレジスタにそのデータが存在するアドレスの番号が記録され、CPUが直接メモリにアクセスしてデータを拾ってくるというわけです。
ただし、CPUから主記憶装置まではレジスタと比べて物理的に距離があるので速度が遅くなってしまうというわけです。
また、参照型のデータをパラメータに指定したときはアドレス番号がパラメータとして設定されます。

メモリのアドレスでしか渡さないので、別のところでそのデータをいじれちゃうんですね。
なので、参照型のデータを渡すときは、メソッド通過後にデータがいつの間にか変わってる!なんてことがなりえることに注意すべきです。
サンプルを見てみましょう。
public void Main() {
A v1 = new A();
v1.Value = 10;
Test(ref A);
// A.val => 20
// Main内のv1とTestメソッド内のobjは同じインスタンス
}
public void Test(ref A obj) {
obj.Value = 20;
}
public class A {
public int Value = 0;
}
値型とは
逆に値型は参照型と違って、データを直接レジスタに置きます。
この場合、CPUはレジスタからアドレス番号を拾い、主記憶装置にアクセス…なんて無駄な処理をせずにすぐに目的のデータにアクセスできるというわけです。なので速いんですね。
ですが注意点があります。
容量の多いデータには向いていない
パラメータや戻り値の指定をするたびにメモリからレジスタにデータを移動させるので、容量の多いデータには向いていません。
某ブログの研究によると値型と参照型の使い分けのラインは4KBだそうです。これはint型が512個と同じ。string型や配列があるとあっという間に超えるのでその辺りで使い分けるべきだと思います。
データの編集はそのメソッド内でのみ有効
これは参照型と真逆です。参照型は呼び出したメソッド内でオブジェクトがあると自分の所のメソッドにもその影響が来るといいました。値型のオブジェクトはその影響がありません。
逆に、指定したオブジェクトを何かしらの操作するメソッドを作るのはどうすればいいのでしょうか
それはref,out,inを使いこなすことです。
refは値型オブジェクトでも参照型オブジェクトのようにすることができます。つまり相手先のメソッドで編集した影響が自分の方にも行くようになるということです。
サンプルを見てみましょう
refが付いていないとこのようになります。
public void Main() {
A v1 = new A();
v1.Value = 10;
// パラメータを渡す際にv1がコピーされて渡される。
Test(A);
// A.val => 10
// Main内のv1とTestメソッド内のobjは別のインスタンス
}
public void Test(A obj) {
obj.Value = 20;
}
public struct A {
public int Value = 0;
}
それがrefをつけることで参照型オブジェクトのようにパラメータ渡しが行われます。
public void Main() {
A v1 = new A();
v1.Value = 10;
Test(ref A);
// A.val => 20
}
public void Test(ref A obj) {
obj.Value = 20;
}
public struct A {
public int Value = 0;
}
これは重要なことです。必ず渡すオブジェクトが値型なのか参照型なのか意識して渡すようにしましょう。
特例: string型に就て
string型だけは特殊です。参照型と値型の両方の特徴を持っています。
と言いますのも、string型はintのような数値型と比べるとオブジェクトの容量が大きくなる傾向にあります。なので参照型と値型のハイブリットな動作をするのです。
ただし、基本的に動作は値型のような動作をします。なので、stringは値型と覚えるのが無難でしょう。